需求描述:判斷顧客是否已經流失,並找出最有價值的顧客。
本篇文章主要是從《What’s a Customer Worth?》來的,不過換了資料集,然後做了翻譯、篩選內容,並增加了一些自己的詮釋。這邊使用的資料集為網站追蹤碼所蒐集到的某電商資料。
原文的作者有特別強調這個分析是針對「非合約性」的交易所做的,因為沒有跟顧客簽訂任何合約,所以無法得知顧客是否已經流失。因此文章下面有人留言問說:「那針對合約性的交易是否也能使用這個方法?」作者回應:基本上「合約性」的交易只要看顧客是否續訂就能判斷是否流失,因此「合約性」的交易反而是回到一般比較常聽到的機器學習上的分類問題。
以下的分析主要出自於 Dr. Peter Fader of Wharton 的論文,使用的工具是 Python 的套件 Lifetimes,由 Shopify 的資料科學家 Cameron Davidson-Pilon 所開發。
資料準備及探索
所需準備的資料蠻單純的,只需要三個欄位:顧客 ID、購買日期、購買金額,這邊我拉了今年(2018)一到八月的資料。
from sqlalchemy import create_engine
import pandas as pdengine = create_engine( [資料庫的連線資訊] )df = pd.read_sql("""SELECT uuid, general_visitAt, transactionTotal
FROM TableName""", con=engine)
df.head()

接著透過套件的函式,將我們的資料轉成待會分析時所需要的欄位,分別將目前的 DataFrame 以及顧客 ID、購買日期、資料最後時間傳入:
from lifetimes.plotting import *
from lifetimes.utils import *
from lifetimes.estimation import *
%matplotlib inlinedata = summary_data_from_transaction_data(df,
'uuid',
'general_visitAt',
observation_period_end='2018-08-31')
data.head()

欄位的內容如下:
- frequency:該名顧客重複購買的次數,也就是總購買次數減一(扣掉第一次購買),因此如果只購買過一次的話,則該欄位值為 0。
- T:文件的說明是該名顧客的年齡(age),但不是一般直覺上的年齡,而是進行第一次購買成為自己顧客後,至今經過了多長的時間,單位可以是日、週、月等等,這邊我使用的單位為日。
- recency:該名顧客最後一次購買時,是年齡(上述的 T)為何的時候,也就是最後一次購買時間減掉第一次購買時間,如果該名顧客只購買過一次則該欄位值為 0。
因此像是上圖的第一筆資料,則是一名年齡 176 天,沒有進行再次購買,因此 frequency 及 recency 皆為 0 的顧客。
接著來簡單看一下資料概況:
data['frequency'].plot(kind='hist', bins=50)
print(data['frequency'].describe())
print(sum(data['frequency'] == 0)/float(len(data)))
這邊可以看到重複購買的資料非常少,有 87.5 % 左右的顧客都只進行一次購買。一般而言,開發新顧客所需要的成本遠大於維繫既有顧客,然而這間電商在今年八個月之內累積了 4–5 千名顧客,這些顧客卻沒有持續購買的動機,多少可以顯示出維繫客戶上的問題。(不過網站追蹤的顧客 ID 是認 cookies 的,所以理論上來說本來就會比較少。)
用 BG/NBD Model 分析 Frequency/Recency
這個分析要解決的問題是:判斷顧客是否已經流失,這邊用的詞為是否存活(alive 或 dead)。這個問題的困難點在於,假設一名顧客每天都進行購買,並且持續了一個月,但最近幾個月卻沒有看到他再次進行購買,那麼在直覺上我們會認定這名顧客已經流失了;而假設有一名顧客每季都有購買紀錄,只是最近一兩個月還沒進行購買的話,那麼他仍然存活(alive)的可能性還是很高。也就是說要判斷一個顧客是否存活時,必須根據他的購買頻率而定,上面的兩個例子都是比較極端、好人為判斷的,但這之間的模糊地帶,有沒有什麼科學方法能夠幫忙做判斷呢?這就是 BG/NBD model 的主要作用。
import matplotlib.pyplot as pltbgf = BetaGeoFitter(penalizer_coef=0.0)
bgf.fit(data['frequency'], data['recency'], data['T'])
fig = plt.figure(figsize=(12,8))
plot_frequency_recency_matrix(bgf)

上面這張圖顯示了未來顧客在單位時間內進行購買的預期值,其中右下角值最高(黃色)的那一區,為該店的最佳顧客群;右上角則為曾經頻繁購買,但近期已經不再有購買行為的流失客戶群;至於在 ( 10, 200 ) 處,則為比較模糊的地帶,可能存活(alive)也可能死了(dead)。因此接下來我們來畫各區顧客存活(alive)的機率圖:
fig = plt.figure(figsize=(12,8))
plot_probability_alive_matrix(bgf)
可以看到剛才說的 ( 10, 200 ),即為已經進行 10 次重複購買,並且最近一次購買是在年齡 200 天的顧客,仍然有 40–60% 的機率是存活的(大概目測一下而已非精準數字)。
從中,我們可以計算出顧客在某單位時間內(下面的 t 值)的預期購買數:
t = 1
data['predicted_purchases'] =
bgf.conditional_expected_number_of_purchases_up_to_time(t,
data['frequency'],
data['recency'],
data['T'])
data.sort_values(by='predicted_purchases').tail(5)
上面列出了下一個單位時間(這邊指隔天)預期購買值最高的五名顧客。
另外也可以預測單一客戶的預期購買值:
t = 10 # 十個單位時間,這邊指未來十天
individual = data.loc['User ID']
bgf.predict(t, individual['frequency'],
individual['recency'],
individual['T'])這邊我的 output 為 1.63。
模型驗證
首先可以先來簡單比對一下實際的資料以及擬合過後的模型值:
plot_period_transactions(bgf)
從圖中可以看出模型的分佈與實際的分佈出入不大,還算是個可以信任的模型。
接著我們將資料分成 calibration period dataset 以及 holdout dataset,這個做法有點像是在做機器學習時,會將資料的 80% 拿來訓練,接著拿剩下的 20% 驗證模型的準確度的感覺。這邊我拿今年 1–7 月的資料 fit model,然後拿最後的 8 月來驗證,並畫圖。注意這邊拿的是一開始的資料 df,非 aggregate 過後的 data。
summary_cal_holdout =
calibration_and_holdout_data(df, 'uuid', 'general_visitAt',
calibration_period_end='2018-07-31',
observation_period_end='2018-08-31'
)
bgf.fit(summary_cal_holdout['frequency_cal'],
summary_cal_holdout['recency_cal'],
summary_cal_holdout['T_cal'])plot_calibration_purchases_vs_holdout_purchases(bgf,
summary_cal_holdout)

藍線為實際資料分佈,橘線為模型的預測分佈。其中 X 軸為 1–7 月時的購買次數, Y 軸為 8 月的平均購買次數。舉例來說,在 1–7 月有進行 3 次購買的顧客,在 8 月平均會購買 0.2 次左右,而模型則是預測 0.1 次左右。
顧客存活機率的歷史變化
fig = plt.figure(figsize=(12,8))
days_since_birth = 92
sp_trans = df.loc[df['uuid'] == 'User ID']
plot_history_alive(bgf,
days_since_birth,
sp_trans,
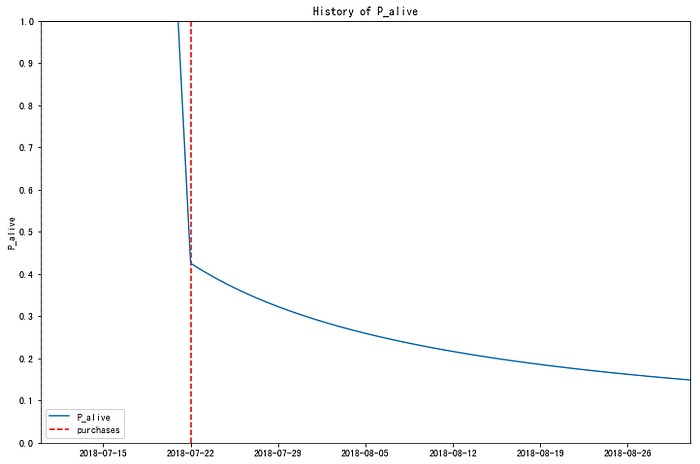
'general_visitAt')可以畫出很有趣的圖:

圖中顯示的是某單一顧客的存活機率變化,首先他在進行第一次購買後,存活機率為 100%,之後存活機率開始隨著時間急速下降,直到他在 6/1 後幾天進行了第一次的重複購買,讓下降的線坡度漸緩,而在 6/15 過後連續幾次的購買都將存活機率大大地拉高,如此便能呈現整個存活機率的變化。不過如果只重複購買過一次的顧客的話,就比較看不出什麼:
顧客價值估算
接著我們用 Dr. Peter Fader 和 Dr. Bruce Hardie 所發表的論文,以 Gamma-Gamma submodel 估算顧客未來單次購買可能的金額。首先,我們要新增欄位,將訂單金額納入計算:
data2 = summary_data_from_transaction_data(df,
'uuid',
'general_visitAt',
monetary_value_col='transactionTotal',
observation_period_end='2018-08-31')接著篩掉未曾重複購買,以及購買金額為 0 的顧客:
returning_customers_summary = data2[ (data2['frequency'] > 0) &
(data2['monetary_value'] != 0)]接著來 fit 模型並印出顧客的價值:
from lifetimes import GammaGammaFitterggf = GammaGammaFitter(penalizer_coef = 0)ggf.fit(returning_customers_summary['frequency'],
returning_customers_summary['monetary_value'])ggf.conditional_expected_average_profit(
returning_customers_summary['frequency'],
returning_customers_summary['monetary_value']
).head(10)

右邊的值則為模型所預測的每個顧客未來單次購買可能的金額。
簡單觀察一下效果,我將九月份的資料拉出來,用 uuid 來 mapping 後:

結果有點微妙,有些蠻準的,有些落差非常大,簡單算了一下 MSE 高達 8 百萬左右。畫個圖:(藍色為預測值,橘色為實際值)

以上,就是 Buy Till You Die 模型的簡單實作。